Final Project (Part I)
Outline
Summary
For the final project, I will analyze my own personal Spotify data, particularly self-curated playlists, from 2019 thus far to formulate a tailored guide that will represent new musical selections for consumption in the upcoming year 2020. Besides pursuing my own data, I am interested in comparing myself versus the “average” U.S. individual, in terms of each group’s musical prospects for 2020.
I was spurred to tackle this project due to skepticism on Spotify’s “Discover” playlists, which seems inconsistent and/or lacks satisfaction. In the Digital Age of the 21st Century, we have permitted computers and algorithms to dictate choice, therefore, I am looking to present a chance to customize musical journeys that align with individuals’ specific musical tastes. Basically, implementing step-by-step analysis instructions. Many Americans, no the world, listen to music on the daily, so why not have the best music that fits you?
Challenges
I do believe that this project will provide challenges. Here are some examples:
- Overwhelming Data: Since I will be collecting data from a year’s worth of music it might provide challenging to compile it all
- Project Simplicity: With the goal of curating two playlists based on interest, might be difficult to have a lot of meaningful content
- Research: Since part of the data collection will require me to do some digging into new musical content, this could be laborious/difficult in selecting appropriate items for the playlists
Project Structure
The project will begin looking at two datasets: Spotify’s Current Top 200 Songs from the U.S. (Pulled 11/13/19) and André Solomon’s 2019 Spotify data (primarily from André created playlists). Looking at both data structures, it ultimately has to be organized into buckets: Genre/Mood, Artists, Albums, and Songs. Since the objective is to discover new songs for consumption, there will be limitations on selected songs, no songs that are found prior 2018 will not be considered. Once songs are put into buckets, the analysis of trend data will commence. For example, knowing that one of my top played genres is “Pop” then I can eliminate genres that do not match that stipulation, and the same principle can be utilized on the remaining buckets. Once the elimination process has been completed, there will be a truncated list of the trend data. Due to the massive amounts of music, there will have to be barriers on selection. Therefore, selection will be based on these guidelines:
- Top 5 Genres
- Top 10 Artists
- Top 20 Albums
- Top 30 Songs
I believe that this will give enough content to conduct a deeper analyzation of the music. (Note the same principle will be applied towards the 2020 selections). After these have been determined, I will have to do some personal digging on both what the average U.S. individual and I should listen to. Ultimately, creating two new playlists. Referring back to the guidelines, the new playlists will involve the same characteristics, enough content to have a solid musical selection for the start of the new year.
User Story/Motivation
For the reader, I want them to understand the process of making music selections with intent, a way to discover music that authentically resonates with their tastes.
Call to Action
Map your musical interests to determine what new music aligns to you personally.
Initial Sketches

The Data
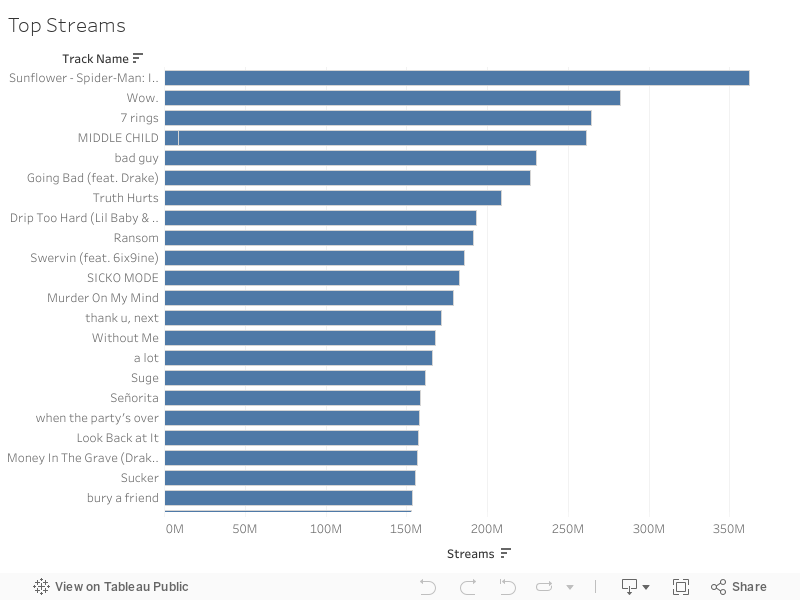
To my advantage, Spotify publicly shares their data. The U.S. Top Charts for 2019 (Songs) can be found on Spotify’s public website which shows the top charts both weekly and daily in various regions in the world.
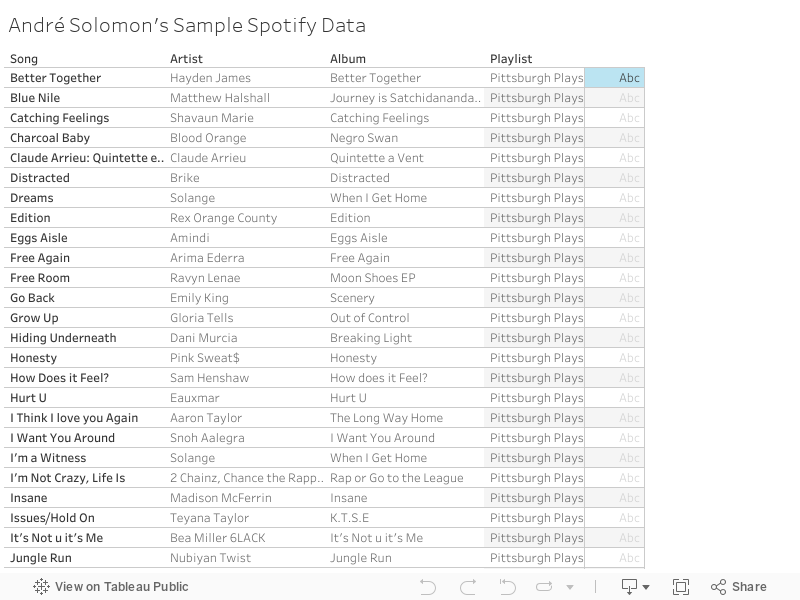
In terms of my own Spotify data anyone with an account (free or premium) can request their own personal data.
Here is the way to obtain it:
- Visit Spotify’s website
- Go to your account page
- Click the Privacy tab
- Scroll all the way down and view the section titled Download your Data
There contains a three-step process where you have to…
- Request the Data
- Wait for the data to be complied (30-day max)
- Download the data (comes in a JSON format)
Here is a sample of my personal Spotify data:
Using the Data
As I mentioned previously, I will use both the United States’ and my Spotify data to structure the top favorite genres, artists, and songs for each participant. Overall, a way to curate two playlists, (one for the U.S. and another for myself) which will allow both parties to tap into new musical content for the start of 2020 that more efficiently gauges interest. Additionally, provide simple instructions for individuals to conduct analysis on their own; a way to give every individual the opportunity to shape their own musical journey. To create these playlists, it will require me to tap into Spotify’s music library and test out new content to determine if it resonates with both parties’ interests.
With Spotify’s Discover feature, I am often skeptical of the methods. Therefore, I will also conduct research that concentrates on the questions: Does Spotify’s discover feature incorporate clout? More so, are well-known artists given the opportunity to be “discovered” over others? Are there monetary transactions that take place? What factors go into understanding an individual’s musical taste?
Lastly, besides the final outcome of creating playlists and conducting critical research, I want to present standard graphs on a Tableau Dashboard that will track stream use and popularity
Method/Medium
Story Platform
For the project I will be utilizing the digital platform Shorthand to map out my data story.
Recording Data & Graphing
For measuring and presenting the data I will take advantage of Tableau to host all of the excel data and Tableau Public to allow my dashboard to be presented publicly with my readers
Brainstorms/Sketches
To collect my thought process throughout this project, I will use a mixture of the digital platform Balsmiq and paper documents